
AI models from OpenAI, Anthropic, and other top AI labs are increasingly being used to assist with programming tasks. Google CEO Sundar Pichai said in October that 25% of new code at the company is generated by AI, and Meta CEO Mark Zuckerberg has expressed ambitions to widely deploy AI coding models within the social media giant.
Yet even some of the best models today struggle to resolve software bugs that wouldn’t trip up experienced devs.
A new study from Microsoft Research, Microsoft’s R&D division, reveals that models, including Anthropic’s Claude 3.7 Sonnet and OpenAI’s o3-mini, fail to debug many issues in a software development benchmark called SWE-bench Lite. The results are a sobering reminder that, despite bold pronouncements from companies like OpenAI, AI is still no match for human experts in domains such as coding.
The study’s co-authors tested nine different models as the backbone for a “single prompt-based agent” that had access to a number of debugging tools, including a Python debugger. They tasked this agent with solving a curated set of 300 software debugging tasks from SWE-bench Lite.
According to the co-authors, even when equipped with stronger and more recent models, their agent rarely completed more than half of the debugging tasks successfully. Claude 3.7 Sonnet had the highest average success rate (48.4%), followed by OpenAI’s o1 (30.2%), and o3-mini (22.1%).
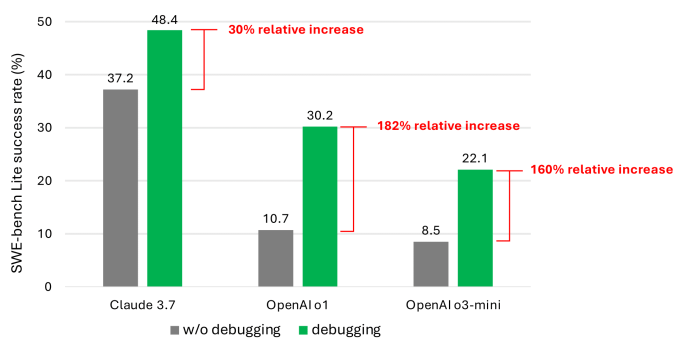
Why the underwhelming performance? Some models struggled to use the debugging tools available to them and understand how different tools might help with different issues. The bigger problem, though, was data scarcity, according to the co-authors. They speculate that there’s not enough data representing “sequential decision-making processes” — that is, human debugging traces — in current models’ training data.
“We strongly believe that training or fine-tuning [models] can make them better interactive debuggers,” wrote the co-authors in their study. “However, this will require specialized data to fulfill such model training, for example, trajectory data that records agents interacting with a debugger to collect necessary information before suggesting a bug fix.”
Disrupt 2026: The tech ecosystem, all in one room
Your next round. Your next hire. Your next breakout opportunity. Find it at TechCrunch Disrupt 2026, where 10,000+ founders, investors, and tech leaders gather for three days of 250+ tactical sessions, powerful introductions, and market-defining innovation. Register now to save up to $400.
Save up to $300 or 30% to TechCrunch Founder Summit
1,000+ founders and investors come together at TechCrunch Founder Summit 2026 for a full day focused on growth, execution, and real-world scaling. Learn from founders and investors who have shaped the industry. Connect with peers navigating similar growth stages. Walk away with tactics you can apply immediately
Offer ends March 13.
The findings aren’t exactly shocking. Many studies have shown that code-generating AI tends to introduce security vulnerabilities and errors, owing to weaknesses in areas like the ability to understand programming logic. One recent evaluation of Devin, a popular AI coding tool, found that it could only complete three out of 20 programming tests.
But the Microsoft work is one of the more detailed looks yet at a persistent problem area for models. It likely won’t dampen investor enthusiasm for AI-powered assistive coding tools, but with any luck, it’ll make developers — and their higher-ups — think twice about letting AI run the coding show.
For what it’s worth, a growing number of tech leaders have disputed the notion that AI will automate away coding jobs. Microsoft co-founder Bill Gates has said he thinks programming as a profession is here to stay. So has Replit CEO Amjad Masad, Okta CEO Todd McKinnon, and IBM CEO Arvind Krishna.

